
Azure Data Factory’s copy operation copies data between different data stores on-premises and in the cloud, uses the copied data from another transform or analysis operation, or copies the transformed or parsed data to the final store where you want to render it.
The copy action supports a variable number of data stores such as Azure data stores, on-premises relational and non-relational data stores, file stores, common protocols such as HTTPS, and applications such as Service Now.
Overview
Azure Data Factory supports reading and writing a variety of file formats including Avro, Binary, Delimited Text, Excel, JSON, ORC, Parquet, and XML file formats. For a complete list of supported data sources (called sources) and data destinations (called sinks), see Supported data stores and formats in the Copy Azure Data Factory Activity.
Azure Data Factory uses IR (Integrated Runtime) as a secure computing infrastructure to perform copy operations in various network environments and ensure operations are performed in the region closest to the data store. You can think of this as the bridge between copy and related services.
Azure Data Factory has supported in three types of integration runtime
- Azure Integration Runtime, used when copying data between public data stores over the Internet.
- Self-Hosted Integration Runtime, used for copying data, local data stores, or networks with access control.
- Azure SSIS Integration Runtime, used to run an SSIS package in a data factory, which will be discussed later in this series. For more information, see the Azure Data Factory Integration Runtime.
You can copy from your data factory using a variety of tools and SDKs, including the Data Copy Tool, Azure Portal, .NET SDK, Python SDK, Azure PowerShell, REST API, and Azure Resource Manager templates.
If you want to copy data from a text file stored in Azure Blob storage to an Azure SQL Database table, you need to make sure you have a storage account with a blob container that contains your data files.

And Azure Data Factory can access this database server with Azure SQL Database with the Allow Azure services and resources to access this server firewall option enabled.

Also, as with the CREATE TABLE T-SQL statement, create a new table in Azure SQL Database to insert data from a text file stored in the BLOB container into the corresponding Azure SQL Database table.

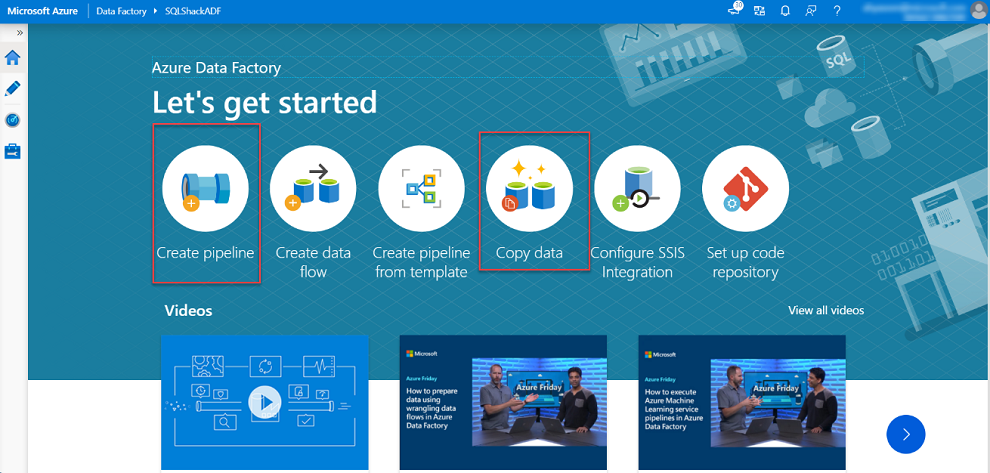
You are now ready to set up a data factory pipeline that will be used to copy data from the blob container to Azure SQL Database. To customize the copy process, open Azure Data Factory in the Azure portal and select the Author and Monitor option on the Overview tab.

You have two options for setting up a copy pipeline in an open data factory. The first option is to manually create pipeline components one by one using the Create Pipeline option. The second option we’ll use in this demo is to use the copy data tool to create a pipeline.
The first step in the data copy tool is to give the copy activity a unique name and indicate whether this copy process should be scheduled or should be run once.

The Copy Data Wizard then will ask you to give the specify type of source data store to create a linked service that will be connected to current data storage. And in this case, you have to copy data from Azure Blob storage.

Select the Azure Blob storage source type and then click Continue, a new window will open where you need to provide a unique name for the associated service, the subscription the storage account was created for, and the storage name. After you have provided all the necessary information and the account you will use to connect to this storage account, click Test Connection to make sure you can access this storage account, then click Create to create the connected service.

After successful creation, the associated service will be displayed in the data source window.

Then, if you need to copy multiple files repeatedly, you just need to specify the input data file or folder and create a dataset for the data source.

When you specify an input file, the data factory can check the format of that file, view the file format settings, preview the source data, and make any necessary changes to suit your requirements.

The next step is to configure the connected service and data set for the target data store. In this demo, the input file is copied to an Azure SQL Database table. To do this, select Azure SQL Database from the list of new linked services, then click Continue to configure the linked listener service.

In the new Linked Services window shown, provide the distinguished name, subscription name, Azure SQL Server and database name of the linked listener service, and finally provide the credentials that will be used the Azure Data Factory to connecting into the Azure SQL Database. After providing all the required information, click the Test Connection option to test the connection between the data factory and the Azure SQL Database, then click New to create the associated service.

Upon successful creation, the sink Linked service is listed in the target data store.

After creating a linked service that points to the sink datastore, you need to create the sink dataset specifying the target database table.

You will also need to review the schema mapping between the input data file and the receiver data table and provide a script to run before copying the data.

You have now successfully configured the relevant services and data sets for the source and target data stores. Now the next step is to tune the copy activity parameters such as performance and fault tolerance parameters.

Before running the Pipeline in the summary window, review all the configurations of the copy process, as well as the ability to edit them in the summary window.

Now you have to checked all the settings for your pipeline and are ready to deploy and run. Data Factory creates all pipeline components and then runs the pipeline. Running a pipeline means performing a copy operation that copies data from an input file stored in Azure Blob Storage and writes it to an Azure SQL Database table.

To verify that the data has been copied to an Azure SQL Database table, you can connect to Azure SQL Database using SSMS and then run a select statement to read the table data and verify that the data was copied successfully.

In this article, we showed you how to copy data between Azure Datastores and validate pipeline components and results. In the following article, you will learn how to use Azure Data Factory to copy data from an on-premises data store to an Azure data store. Get in touch!

AUTHOR BIO
On my daily job, I am a software engineer, programmer & computer technician. My passion is assembling PC hardware, studying Operating System and all things related to computers technology. I also love to make short films for YouTube as a producer. More at about me…


















Leave a Reply